REVIVE 3D
Refinement via Encoded Voluminous Inflated Prior for Volume Enhancement
REVIVE 3D generates voluminous 3D assets from flat images.
Abstract
Flat Image to 3D Generation
Explore four generated meshes per page. We provide twelve image-conditioned generation results in total.
Comparison with Baselines
Editing Results
Method
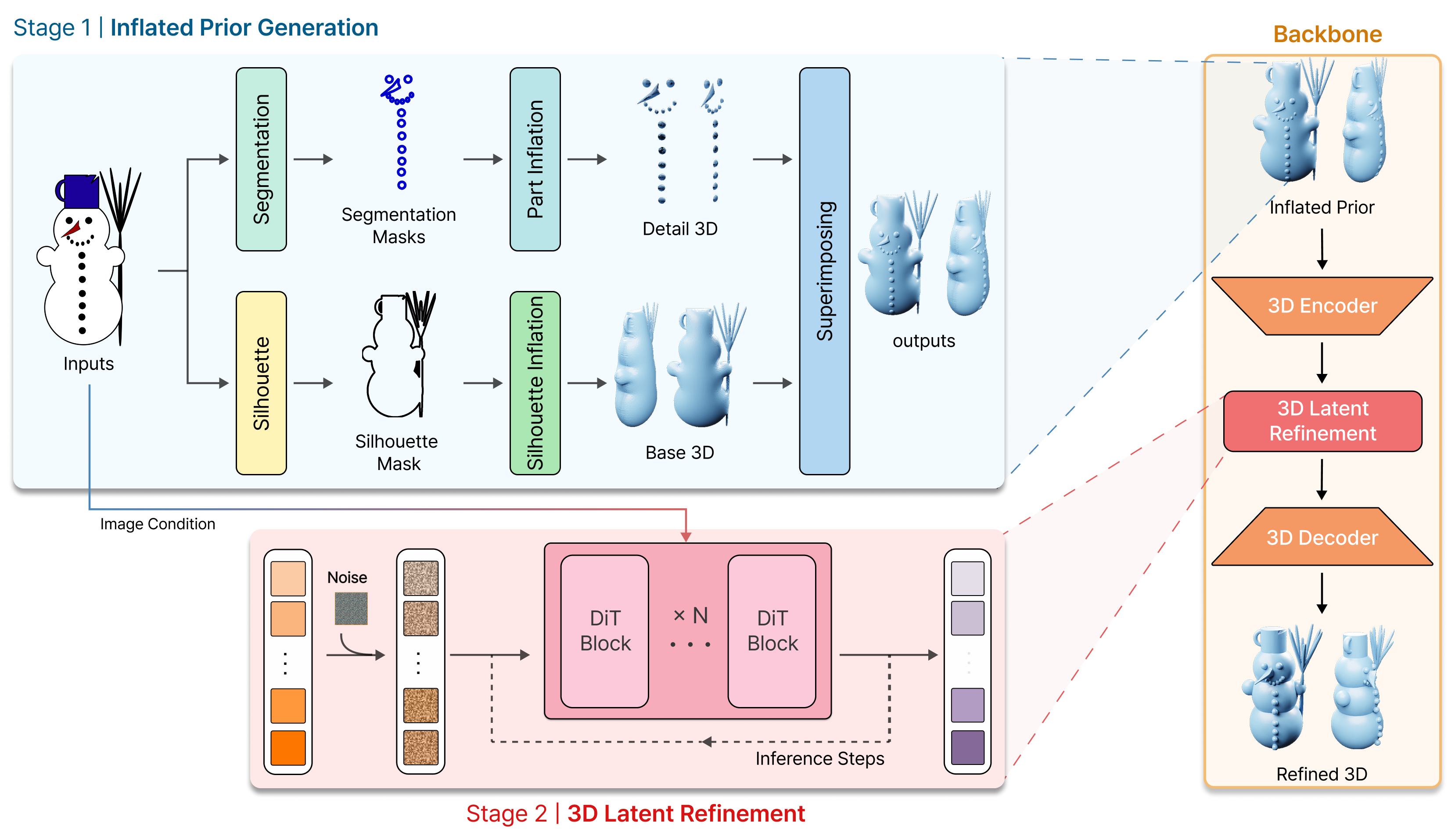
Inflated Prior
We recover missing volume from the foreground silhouette and add part-aware local cues through superimposing.
3D Latent Refinement
We refine the inflated prior in the backbone latent space to obtain geometry that is both more plausible and more image-consistent.
Overview of our method. Stage 1 generates the Inflated Prior. We create a Base 3D from the Silhouette Mask and Detail 3D from Segmentation Masks, then combine them via superimposing. Stage 2 refines the Inflated Prior by encoding the mesh, injecting noise, denoising it with the image condition, and decoding the result into the Refined 3D mesh.
Quantitative Results
Uni3D and ULIP show that our results are the most semantically aligned with the input image, while Compactness (C) and Normal Anisotropy (NA) show that they are the most voluminous and the least flat.
| Models | Uni3D ↑ | ULIP ↑ | C ↑ | NA ↓ |
|---|---|---|---|---|
| Trellis | 0.2736 | 0.1241 | 0.1748 | 0.1282 |
| DrawingSpinUp | 0.2335 | 0.1164 | 0.1604 | 0.1332 |
| Hunyuan3D-Omni | 0.2816 | 0.1257 | 0.1707 | 0.1120 |
| Direct3D | 0.2796 | 0.1315 | 0.2012 | 0.1019 |
| Hunyuan3D-2.1 | 0.2759 | 0.1193 | 0.1408 | 0.1347 |
| Ours (Hunyuan3D-2.1) | 0.3043 | 0.1265 | 0.2179 | 0.0767 |
| Ours (Direct3D) | 0.3097 | 0.1375 | 0.2178 | 0.0908 |
BibTeX
@inproceedings{lee2026revive3d,
author = {Lee, Hankyeol and Baek, Wooyeol and Kim, Seongdo and Kim, Jongyoo},
title = {REVIVE 3D: Refinement via Encoded Voluminous Inflated Prior for Volume Enhancement},
booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference},
year = {2026}
}